Associated thesis
This repository is part of a Master’s thesis with full documentation available at https://tom.vincent-peters.de/master/.
KSquares
KSquares is an implementation of the game squares
AI opponents
Easy
Rule based ai. Knows not to give away boxes, chooses chains at random.
Medium
Rule based ai. Like Easy, but opens shortest chain first.
Hard
Rule based ai. Like Medium, but is able to do Double Dealing to keep the game under control.
Very Hard
Alpha-Beta search algorithm.
Dabble
Alpha-Beta search algorithm in a windows application that is run with wine.
QDab
MCTS with neural network. Can only play on 5x5 boards.
Knox
Alpha-Beta serach algorithm. Slightly unstable. Executed with wine.
MCTS A,B,C
Monte-Carlo Tree Search algorithm which uses Easy (A), Medium (B) or Hard (C) AI for the simulation step.
ConvNet
Interface for direct play against various neural networks. In the AI configuration dialog, you can select the network with the AlphaDots model drop down list.
MCTS ConvNet
Like MCTS A,B,C but uses ConvNet for simulation.
You can find the code in src/aiConvNet.[h|cpp].
AlphaZero
MCTS as described in the paper about AlphaZero
Relevant code files:
src/aiAlphaZeroMCTS.[h|cpp]
src/AlphaZeroMCTSNode.[h|cpp]There is a test suite called alphazero that tests if the MCTS actually finds new smart moves that the network would not have made.
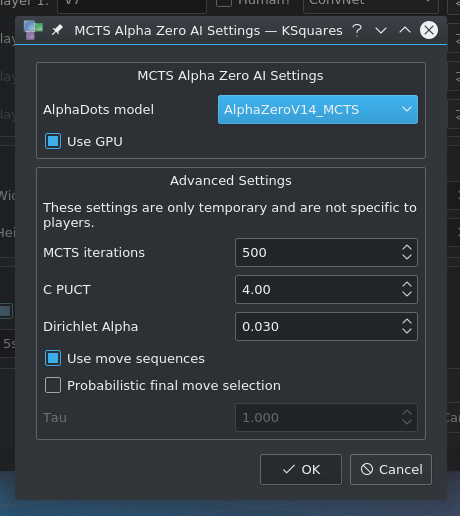
This AI offers the following hyperparameters and configuration options:
--hp-mcts-iterations INTnumber of MCTS iterations. The default value is 1500--hp-mcts-cpuct FLOATthe C_puct value which controls exploration vs. exploitation. The default value is 10.0--hp-mcts-dirichlet-alpha FLOATthe alpha parameter for the dirichlet noise that is applied to the children of the MCTS root node. Default: 0.03--hp-mcts-no-move-sequenceswhen this flag is set, the AI will not use move sequences but only single lines for each node in the Monte-Carlo tree. A move sequence can contain more than one line and represents a full move by a player. For example: In a situation where a player can capture a chain, the algorithm will generate a sequence where it does Double-Dealing on the chain and it will also generate other sequences where it fully captures the chain and then draws another available line. Move sequences reduce the search space by using knowledge specific to Dots and Boxes. Settings this flag will disable the use of this knowledge.--hp-mcts-use-probabilistic-final-move-selectionenables probabilistic final move selection instead of always selecting the highest rated move. MCTS generates a probability distribution over all direct children of the root node. Usually, the move with the highest probability is selected, ignoring the other moves with lower probabilities. By setting this flag, a decision is made according to the generated probability distribution.--hp-mcts-tau FLOATcontrols the probability distribution when selecting the final move. Defaults to 1. For lower values than 1.0 the distribution favors moves with higher probability while for values greater than 1.0 the probabilities equalize. Tau is only used when--hp-mcts-use-probabilistic-final-move-selectionis active.--hp-mcts-use-think-timeconfigures the algorithm to honor the think time. By default, the MCTS algorithm is only limited by the number of iterations. When set to use think times, it will still be limited by the number of iterations.
You can also set most hyperparameters in the GUI:
Tests
You can run various test suites with CMAKE_BUILD_DIR/test/ksquarestest. Call ksquarestest without arguments to execute all available test suites. You can select individual test suites by passing their name as arguments. For example:
ksquarestest hardai berlekampEach test suite is based on QTest Options after -- are passed to QTest. The following example will list all tests in the hardai test suite.
ksquarestest hardai -- -functionsThe test suites are:
berlekamphardaiaiboardalphazeroGSLTestSharedPointer
For more details take a look at the tests page.
AlphaDots in KSquares
AlphaDots uses KSquares for
- generating training data for AlphaDots
- viewing training data
- evaluating trained models
- playing Dots and Boxes
Setup
Please make sure to correctly configure AlphaDots in KSquares by entering the Alpha Dots directory in KSquares -> Settings -> Configure KSquares -> Computer Player.
Clone this git repository to get Alpha Dots:
git clone https://github.com/ofenrohr/alphaDots.gitYou might also want to install tensorflow-gpu in python for GPU acceleration.
Data generators
You can generate training data by running ksquares with certain command line arguments. To explore some of the datasets with a graphical user interface, run this:
ksquares --show-generateYou can only have one board size per dataset. Models can be trained on many datasets of different size.
All dataset generators accept the following optional command line arguments:
--dataset-destDestination directory for the data (.npz file)--dataset-widthBoard width in boxes--dataset-heightBoard height in boxes--threadsNumber of threads
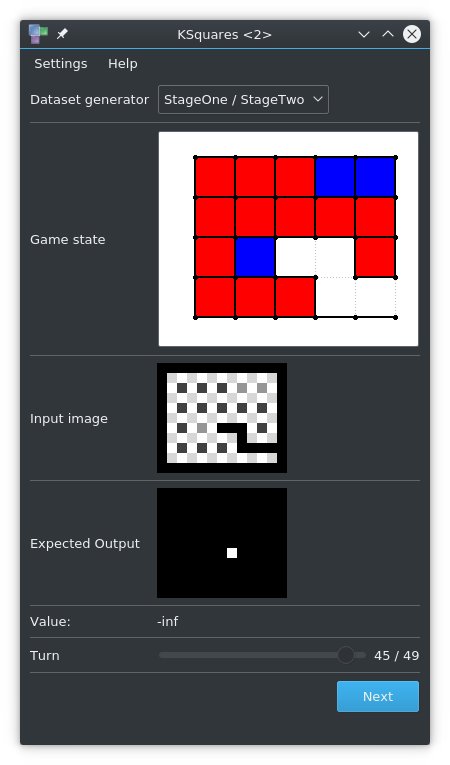
StageOne / StageTwo data generator
{kind=link}
{kind=link}
{kind=link}
{kind=link}
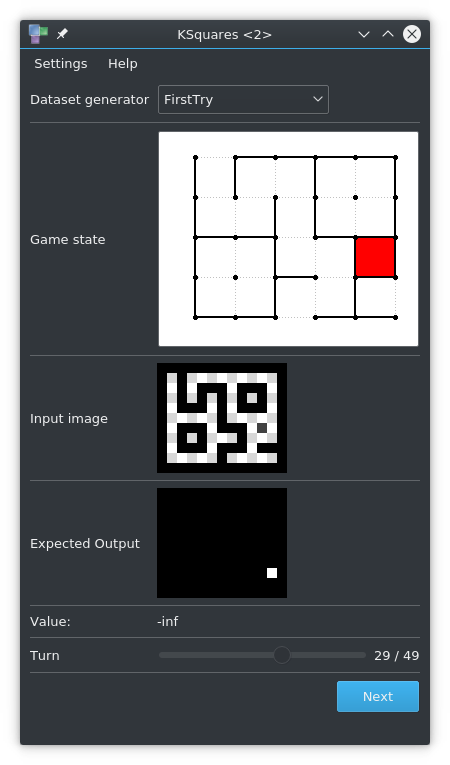
First Try
Converts random Dots and Boxes games played by the Hard AI to images. One training example consists of two images:
- The current state of the game in the input image
- The next line chosen by the Hard AI in the target image
All data is written to disk as actual .PNG images. Input and target images share the same sample UUID.
After generating the training data images, a python script needs to be run to convert the images to a numpy array.
mkdir firstTryDataset
ksquares --generate 1000 --dataset-generator firstTry --dataset-dest firstTryDataset
../alphaDots/datasetConverter/convert.py --dataset-dir firstTryDataset --output-file firstTry.npz --debug

Stage One
The input and target images are no longer generated as individual image files but are sent directly to the python script instead. Communication is facilitated with zeroMQ which is used to send images that were serialized with the protobuf library.
This dataset also introduces weak (random) moves so that there are examples of early captures. 10% of all samples end with a random move. The target image is always made with the reaction of the Hard AI. Due to an oversight, the first version had a bug so that 90% of all samples were made with a random move. Models trained with the buggy version include StageOne and AlphaZeroV1,V2,V3.
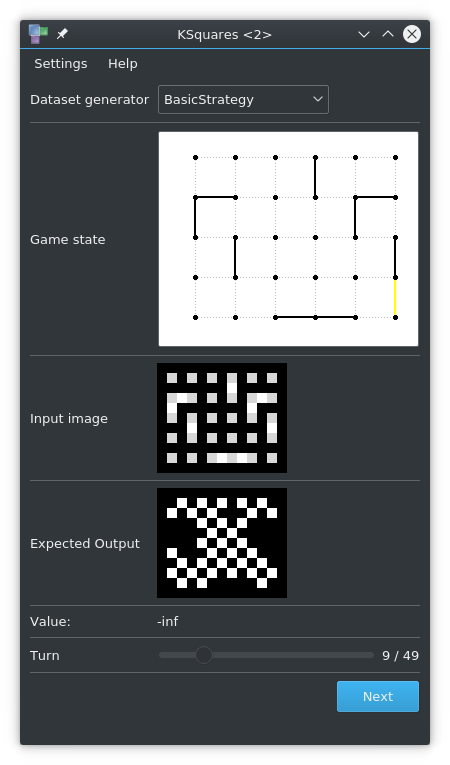
ksquares --generate 1000 --dataset-generator stageOne --dataset-dest /mnt/DATA/stageOneDataset --dataset-width 7 --dataset-height 5Basic Strategy
During the first phase of a Dots and Boxes game, there is a very large amount of acceptable lines. Usually the Hard AI just selects one of those many lines at random. The trained neural network does not know that there are many alternatives to the shown target image. This dataset aims to remedy this by putting all viable lines in one target image.
ksquares --generate 1000 --dataset-generator basicStrategy --dataset-width 7 --dataset-height 5

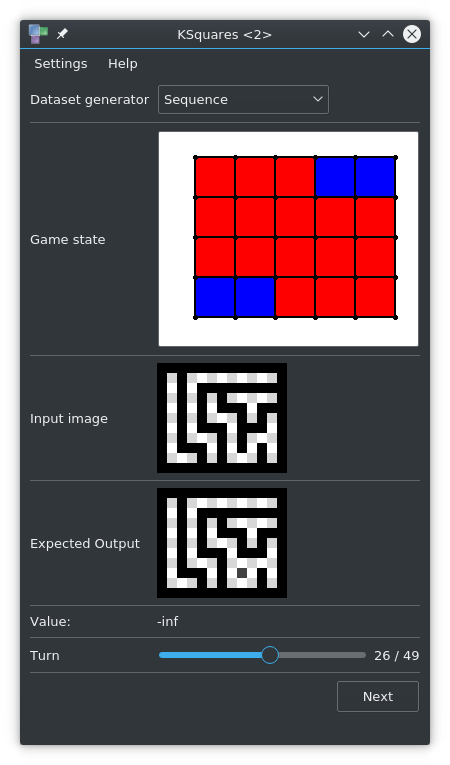
Sequence
Despite the efforts in Basic Strategy, the trained models were not able to compete even with the Medium AI. The main innovation compared to the Easy AI is the ability to count chains - i.e. only handing over the chain with the least amount of squares. To do this, an AI needs to count the number of squares in each chain and decide accordingly.
Previous datasets were used as training data for convolutional neural networks, which lack the ability to count things. As a consequence, a new model is based on convolutional LSTM layers. That model needs another type of training data - only the last state of the game is not enough, it also needs all states leading up to it.
This dataset is made of full Dots and Boxes games, played by two Hard AIs.
ksquares --generate 1000 --dataset-generator LSTM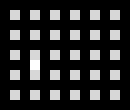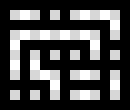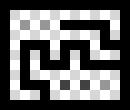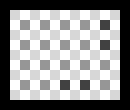
Training Sequence
This dataset is like the Sequence dataset but with “Basic Strategy” target images.
ksquares --generate 1000 --dataset-generator LSTM2Stage Two
The data is generated just like Stage One, but this dataset generator uses cnpy to directly write the .npz file. This removes the overhead of sending the data to a separate, single-threaded python process. As a result, this dataset generator can fully utilize the CPU and is much faster.
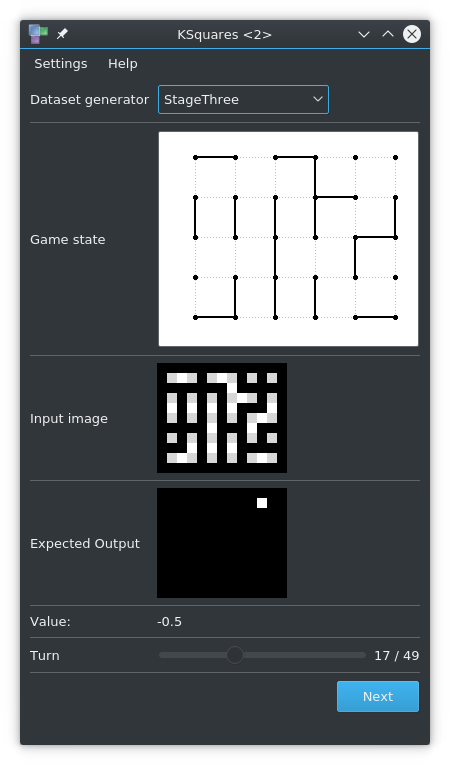
ksquares --generate 1000 --dataset-generator StageTwo --threads 8Stage Three
Data is generated like in Stage Two but the policy is not saved as an image but as a vector of lines. StageThree additionally offers a value output for models like AlphaZeroV6 and up. The value is designed to approximate the chance of winning the game where 1 means winning and -1 means losing the game. It is calculated by playing the game to its end and then evaluating the number of captured boxes for each side as follows:
value = (OwnBoxes - EnemyBoxes) / (0.8 * TotalBoxes)Create a Stage Three dataset by running:
ksquares --generate 1000 --dataset-generator StageThree --threads 8Stage Four / Stage Four (no MCTS)
This dataset generator comes in two flavors: with and without AlphaZero MCTS. The version with MCTS uses KSquare’s Hard AI and AlphaZero MCTS to generate data. As a result, it is possible to use this dataset generator to implement a simplified self-play loop.
Data is generated as follows:
- First, a game is played by KSquare’s Hard AI until a certain number of moves are left. This state is used as input data.
- Afterwards, the corresponding output data (i.e. the next move) is calculated by AlphaZero MCTS, which uses a configurable neural network. If the dataset generator is configured without MCTS, KSquare’s Hard AI will be used instead.
- (no MCTS) Finally, the game is played to its end by KSquare’s Hard AI, so that the game’s value can be calculated.
- (with MCTS) The value is taken from the root node in the Monte-Carlo tree.
In summary the Stage Four dataset generator uses AlphaZero MCTS for exactly one move to minimize computational cost while still providing means to improve upon the neural network.
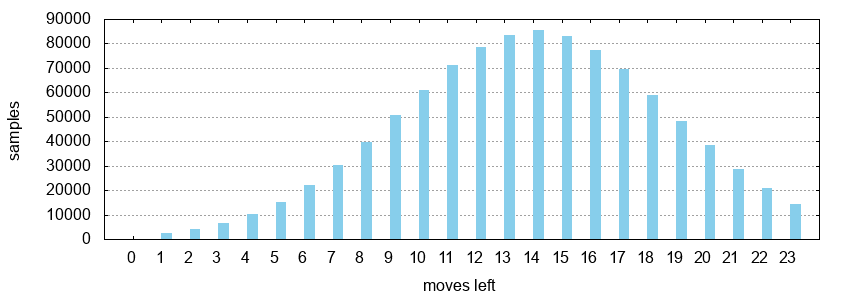
The number of moves that are left before the AlphaZero MCTS calculates its move is determined randomly according to a gaussian normal distribution. The distribution is scaled according to the number of lines so that most samples are in the middle of the game. The following figure shows a histogram for 1.000.000 samples on a 3 x 3 board, which has 24 lines:
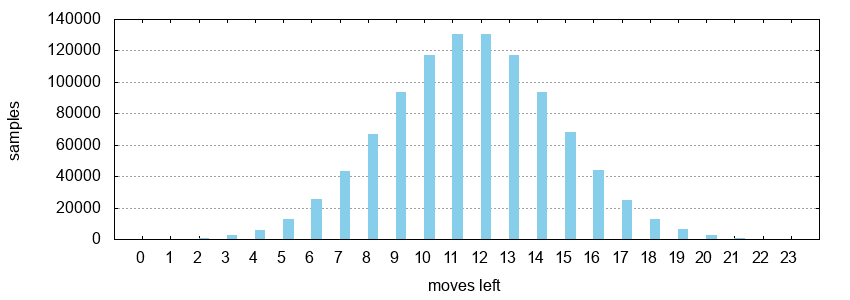
The value from the selected child node is used. In case of not using MCTS, the value is calculated as follows:
value = (OwnBoxes - EnemyBoxes) / TotalBoxesCreate a Stage Four dataset with one of the following commands:
ksquares --generate 16 --dataset-generator StageFour --threads 8 --gpu
ksquares --generate 1000 --dataset-generator StageFourNoMCTS --threads 8The StageFour dataset generator offers two hyperparameters:
--hp-sigma-scalescales the variance of the moves left distribution. The default is set to 0.125. Lower values result in more samples close to the mean value, while higher values result in more evenly distributed distribution.--hp-mean-scalemoves the mean value of the moves left distribution. The default is set to 0.5, so that the most examples are in the middle.
Model evaluation
The are two options to evaluate the trained models. The first option uses the native KSquares Dots and Boxes engine and displays all games while the second option is optimized for fast evaluation. In both cases, a selection of models will be evaluated by playing against the KSquares AIs Easy, Medium and Hard.
Slow GUI evaluation
Start the slow, GUI based model evaluation with:
ksquares --model-evaluationFast evaluation
Start the multi-threaded fast model evaluation with:
ksquares --fast-model-evaluation --threads 8Common arguments
Both evaluation modes support the following optional arguments:
--models MODELSBy default, all models will be evaluated. If you are only interested in a specific subset, use this optional argument. You can get a list of all available models withksquares --model-list--opponent-models MODELSThis parameter selects the models to evaluate against. By default the built-in AIsEasy,MediumandHardare used.--dataset-width WIDTHBoard width measured in boxes.--dataset-height HEIGHTBoard height measured in boxes.--gpuAllow the model server to use the GPU.--report-dir DIRECTORYOutput directory for the report. If this option is present, the model evaluation will save a report and quit immediately afterwards.--analyse-double-dealingBy setting this flag, the Double Dealing analysis module will count the instances of Double dealing that were executed by the models. Double Dealing moves by opponent models will not be counted.--no-quick-startDisables the quick start functionality. By default the model evaluation initializes the board with a few random lines to save time.--think-timeSets the time in milliseconds that an AI has to find a move. The AlphaZero AI will only honor think times if--hp-mcts-use-think-timeis set.
Example results
All games are played on a 5x5 board. The 5x5 board size is reserved for evaluation. No model was ever trained on any dataset with 5x5 boards.
| Model | Games | Wins vs. Easyin 100 games | Wins vs. Mediumin 100 games | Wins vs. Hardin 100 games | Errors |
|---|---|---|---|---|---|
| FirstTry | 300 | 1 | 0 | 0 | 0 |
| StageOne 3x3 | 300 | 58 | 27 | 6 | 0 |
| StageOne 5x5 | 300 | 0 | 1 | 0 | 0 |
| BasicStrategy | 300 | 55 | 27 | 7 | 0 |
| AlphaZeroV1 | 300 | 82 | 80 | 35 | 0 |
| AlphaZeroV3 | 300 | 79 | 94 | 50 | 0 |
| AlphaZeroV5 | 300 | 90 | 75 | 45 | 0 |
| AlphaZeroV7 | 300 | 96 | 80 | 46 | 0 |
| AlphaZeroV14 | 300 | 43 | 39 | 12 | 0 |
| AlphaZeroV14_MCTS | 300 | 93 | 84 | 60 | 0 |
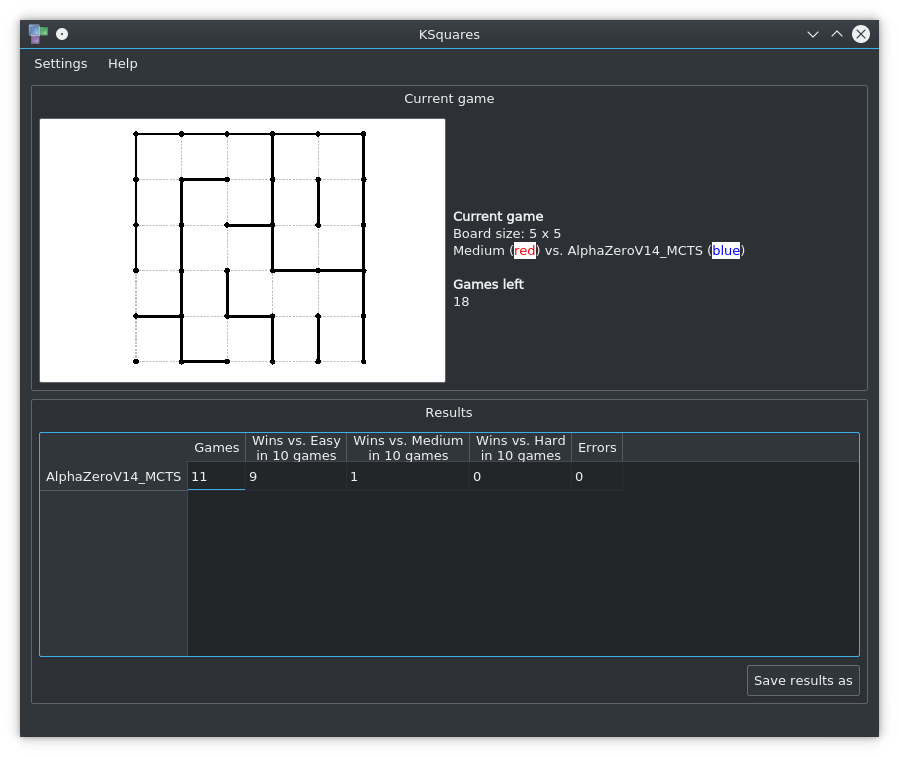
The button Save results as will create an extensive report in markdown format. Here is an example model evaluation report that was rendered from the markdown file.
Screenshot
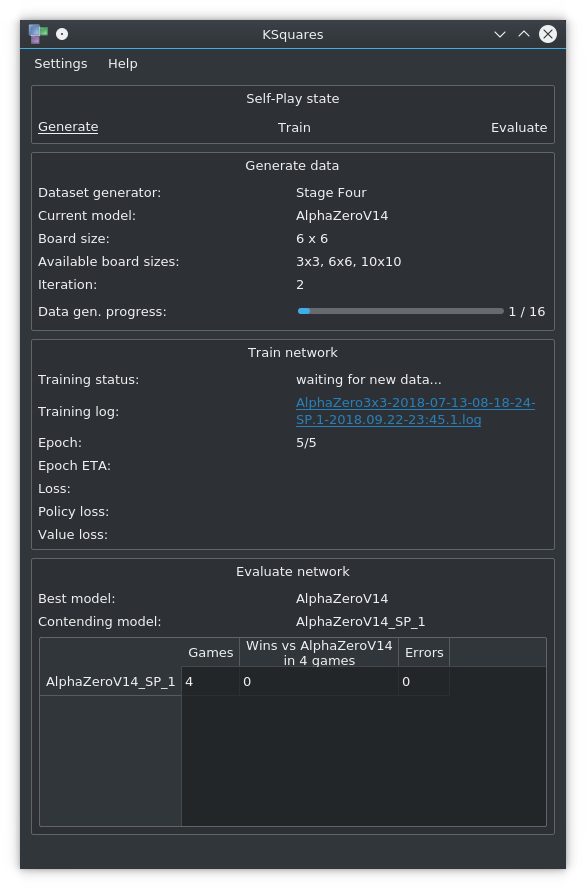
Self-Play
KSquares can operate a self-play loop which works as follows:
- KSquares generates a chunk of training data with the StageFour dataset generator
- KSquares then trains a neural network on that data
- KSquares compares the abilities of the new network in N games against the generator network. If the contending network wins at least half of the games, it becomes the generator network.
Each iteration uses the best network to generate new training data. By default, self-play starts with AlphaZeroV7 as the best network. The self-play mode supports two settings for the --data-generator option: StageFour, which is the default and StageFourNoMCTS, which is useful for generating data with rule based AIs. After it generated the data, KSquares trains the target model on the generated data.
In the first iteration, KSquares creates the target model if it does not exist. Every training process is logged separately. To train the next iteration of a network, KSquares calls AlphaZeroV10.py with appropriate arguments. Training can be done on the CPU or GPU, depending on if --gpu-training is set. If the --cumulative-training flag is set, KSquares will use the network from the previous iteration as the starting point for training, even if it did not win in the evaluation. Without cumulative training, KSquares will base the training on the best network, that was also used to generate data. During self-play each version of the model will be saved separately with a _#iteration suffix, while the normal model name references the best version.
After training, KSquares will evaluate the new model against the best model, that was used to generate data. If the new model wins at least half of the games, it becomes the best model and as a result it will be used to generate data in the next iteration. Depending on the AI configuration in the models.yaml file, the evaluation will either use direct play (ConvNet) or MCTS.
Self-Play in KSquares can be started as follows:
ksquares --self-play --initial-model AlphaZeroV7 --target-model MyNewModelV1Self-Play arguments
The following optional arguments will be considered by self-play:
--gpuenables GPU acceleration of the data generator. Training the network will not use GPU acceleration, because it only takes a fraction of the overall time.--gpu-trainingenable GPU acceleration for the training python script.--threads Nnumber of thread to use when generating data with the MCTS AI (StageFour dataset). Default: 4--iterations Nnumber of self-play iterations to run. Default: 50--iteration-size Nnumber of samples to generate per iteration--initial-model MODELthe name of the model to start generating training data with. Default:alphaZeroV7--target-model MODELthe name of the model to improve in self-play. If the model does not exist, it will be created.--debugprint debug information for individual prediction requests. Settings this flag will slow things down considerably.--debug-mctsprint debug output about the AlphaZeroMCTS algorithm.--dataset-generator GENERATORselect the dataset generator. Supported generators are:StageFourthe StageFour dataset generatorStageFourNoMCTSthe StageFour dataset generator Hard AI instead of MCTS
--dataset-ai NAMEsets the AI used by theStageFourNoMCTSgenerator. Can be set toeasy,mediumorhard. Default:hard--epochs Nnumber of epochs in training.--board-sizes SIZESsets the board sizes in boxes on which the self-play mode will operate. Default value: 4x3,5x4,6x5,7x5,8x8,14x7,14x14,10x9. Board lengths must be at least 2 and at most 20.--no-evaluationdisables the evaluation step.--games Nnumber of games in the evaluation step.--report-dir DIRECTORYDestination directory for the evaluation reports. If this option is set, KSquares will quit immediately after it finished the last iteration.--cumulative-trainingDo not discard networks if they did not win the evaluation.
Please be aware that the self-play mode honors hyperparameters for the StageFour dataset generator and the AlphaZero MCTS AI.
Using the self-play mode for training
It is possible to generate data very fast with the StageFourNoMCTS dataset generator and train a network on that data with KSquare’s self-play mode. StageFourNoMCTS data is generated purely with the Hard AI. So there is no improvement loop, just data generation and training with this setup.
ksquares --self-play --iteration-size 10000 --threads 8 --gpu-training --dataset-generator StageFourNoMCTS --initial-model AlphaZeroV11 --target-model AlphaZeroV11 --epochs 3 --no-evaluationAlphaZeroV11 was trained for 38 iterations with a iteration size of 10,000 after it was created with the IPython Notebook.
Screenshot